「wait/until/current_url」を実行することで特定文字列を含むURLを取得するまで待機することが出来ます。
下記サンプルではまず初めに、「Wait」コンストラクタの引数に(※1)オプション(ここでは:timeout)と待ち時間(秒数)を指定して、インスタンスを作成しています。
次に作成されたインスタンスに対して「until」メソッドを実行しています。「until」メソッドは、引数に指定された条件が真になるまで待機するメソッドです。下記サンプルではdriver.current_urlの形でカレントURLを取得し、期待するURLであるかどうか確認しています。つまり総合すると指定したURLを取得するまで待つということになります。もし「wait」コンストラクタで指定した待ち時間を越えても、期待したURLを取得できない場合はerrorが発生します。
(※1)オプションは「:timeout」、「:interval」、「:message」、「:ignore」の4種類あります。「:interval」はポーリング間隔で、値には秒数を指定します。「:message」はタイムアウトが発生した場合に出力するException mesageを指定します。「:ignore」はポーリングしているときにどのExceptionを無視するか指定します。また、複数のオプションを利用する場合は以下のようにカンマで区切ります。
Wait.new(:timeout => 3, :message => "Test Failed")
説明
◆メソッド
・Wait.new(:timeout => xxx) :Waitコンストラクタにオプションと秒数を指定
・wait.until {true} :中括弧内の条件が「真」になるまで待機する
・driver.current_url :URLを取得する
◆使用形態
・wait.until {driver.current_url == string}
◆備考
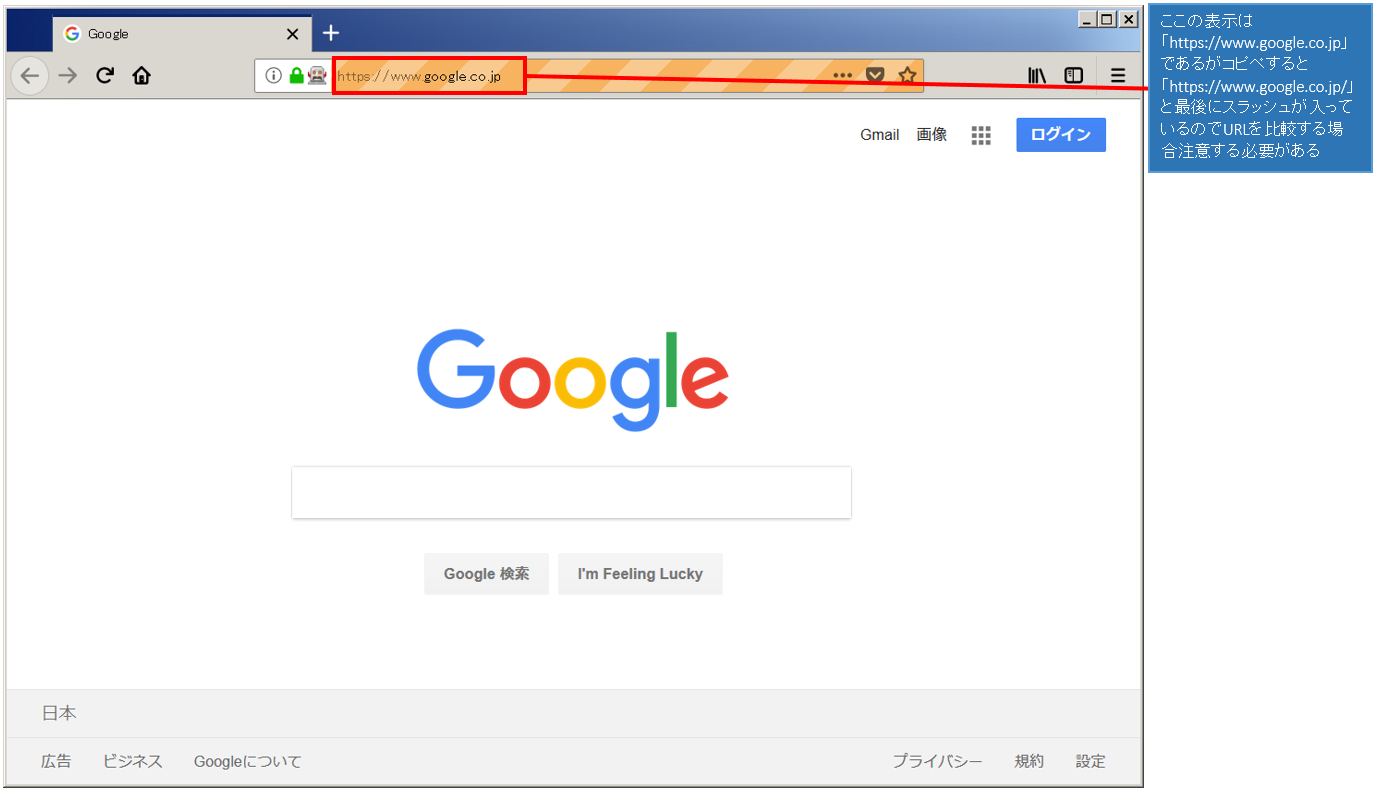
・URLの判定は大文字と小文字を区別する
◆関連項目
・指定した要素が表示/非表示になるまで待機する
・指定した要素が有効になるまで待機する
サンプル
require 'selenium-webdriver'
# Firefoxを起動
driver = Selenium::WebDriver.for(:firefox)
#指定したURLに遷移する
driver.get('https://www.google.co.jp')
#指定したdriverに対して最大で10秒間待つように設定する
wait = Selenium::WebDriver::Wait.new(:timeout => 10)
#確認したいURLを指定する
pageURL = 'https://www.google.co.jp/'
#指定したURLを取得できるまで待機する(最大待機時間までに)
wait.until {driver.current_url == pageURL}
※selenium version 4.1.0で動作確認をしています(ブラウザのUIや属性値などが変更された場合、実行結果が異なる可能性があります)
実行結果